
Introduction
Dans le passé, l’IA générative a conquis le marché et, par conséquent, nous disposons désormais de différents modèles avec différentes applications. L’évaluation de la Gen AI a commencé avec l’architecture Transformer, et cette stratégie a depuis été adoptée dans d’autres domaines. Prenons un exemple. Comme nous le savons, nous utilisons actuellement le modèle VIT dans le domaine de la diffusion stable. Lorsque vous explorez le modèle plus en détail, vous verrez que deux types de services sont disponibles : les services payants et les modèles open source dont l’utilisation est gratuite. L’utilisateur qui souhaite accéder aux services supplémentaires peut utiliser des services payants comme OpenAI, et pour le modèle open source, nous avons un Hugging Face.
Vous pouvez accéder au modèle et selon votre tâche, vous pouvez télécharger le modèle respectif à partir des services. Notez également que des frais peuvent être appliqués pour les modèles de jetons en fonction du service respectif dans la version payante. De même, AWS fournit également des services comme AWS Bedrock, qui permettent d’accéder aux modèles LLM via l’API. Vers la fin de cet article de blog, discutons de la tarification des services.
Objectifs d’apprentissage
- Comprendre l’IA générative avec Stable Diffusion, LLaMA 2 et Claude Models.
- Explorer les fonctionnalités et capacités des modèles Stable Diffusion, LLaMA 2 et Claude d’AWS Bedrock.
- Explorer AWS Bedrock et sa tarification.
- Découvrez comment exploiter ces modèles pour diverses tâches, telles que la génération d’images, la synthèse de texte et la génération de code.
Cet article a été publié dans le cadre du
streamlit run app.py
Qu’est-ce que LLaMA 2 ?
LLaMA 2, ou Large Language Model of Many Applications, appartient à la catégorie des Large Language Models (LLM). Facebook (Meta) a développé ce modèle pour explorer un large spectre d’applications de traitement du langage naturel (NLP). Dans les séries précédentes, le modèle « LAMA » constituait le point de départ du développement, mais il utilisait des méthodes obsolètes.
Principales caractéristiques de LLaMA 2
- Polyvalence: LLaMA 2 est un modèle puissant capable de gérer diverses tâches avec une grande précision et efficacité
- Compréhension contextuelle : Dans l’apprentissage séquence à séquence, nous explorons les phonèmes, les morphèmes, les lexèmes, la syntaxe et le contexte. LLaMA 2 permet une meilleure compréhension des nuances contextuelles.
- Apprentissage par transfert: LLaMA 2 est un modèle robuste, qui bénéficie d’un entraînement approfondi sur un grand jeu de données. L’apprentissage par transfert facilite son adaptabilité rapide à des tâches spécifiques.
- Open source: En Data Science, un aspect clé est la communauté. Les modèles open source permettent aux chercheurs, aux développeurs et aux communautés de les explorer, de les adapter et de les intégrer dans leurs projets.
Cas d’utilisation
- LLaMA 2 peut vous aider création de génération de texte tâches, telles que écriture d’histoires, création de contenuetc.
- Nous connaissons l’importance de l’apprentissage sans tir. Nous pouvons donc utiliser LLaMA 2 pour répondre aux questions tâches, similaires à ChatGPT. Il apporte des réponses pertinentes et précises.
- Pour la traduction linguistique, sur le marché, nous avons des API, mais nous devons nous abonner. Mais LLaMA 2 fournit une traduction linguistique gratuitement, ce qui le rend facile à utiliser.
- LLaMA 2 est facile à utiliser et constitue un excellent choix pour développer des chatbots.
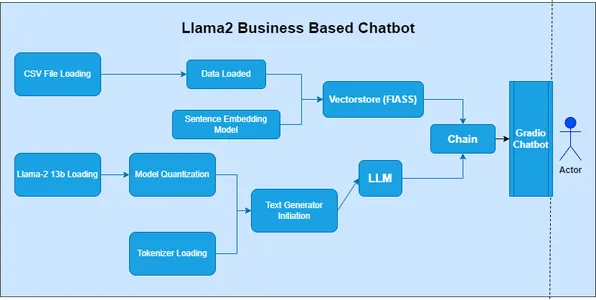
Comment construire LLaMA 2
Pour créer LLaMA 2, vous devrez suivre plusieurs étapes, notamment la configuration de votre environnement de développement, l’accès au modèle et son appel avec les paramètres appropriés.
Étape 1 : Importer des bibliothèques
- Dans la première cellule du notebook, importez les bibliothèques nécessaires :
import boto3
import json
Étape 2 : Définir l’invite et le client AWS Bedrock
- Dans la cellule suivante, définissez l’invite de génération du poème et créez un client pour accéder à l’API AWS Bedrock :
prompt_data = """
Act as a Shakespeare and write a poem on Generative AI
"""
bedrock = boto3.client(service_name="bedrock-runtime")
Étape 3 : Définir la charge utile et invoquer le modèle
- Tout d’abord, examinez l’API dans AWS Bedrock.
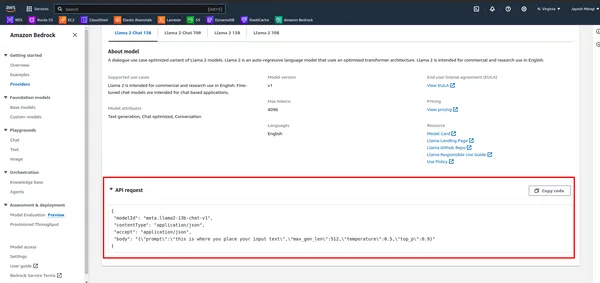
- Définissez la charge utile avec l’invite et d’autres paramètres, puis appelez le modèle à l’aide du client AWS Bedrock :
payload = {
"prompt": "[INST]" + prompt_data + "[/INST]",
"max_gen_len": 512,
"temperature": 0.5,
"top_p": 0.9
}
body = json.dumps(payload)
model_id = "meta.llama2-70b-chat-v1"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
response_text = response_body['generation']
print(response_text)
Étape 4 : Exécutez le bloc-notes
- Exécutez les cellules du bloc-notes une par une en appuyant sur Maj + Entrée. La sortie de la dernière cellule affichera le poème généré.
Étape 5 : Créer une application Streamlit
- Créer un script Python : créez un nouveau script Python (par exemple, lama2_app.py) et ouvrez-le dans votre éditeur de code préféré
import streamlit as st
import boto3
import json
# Define AWS Bedrock client
bedrock = boto3.client(service_name="bedrock-runtime")
# Streamlit app layout
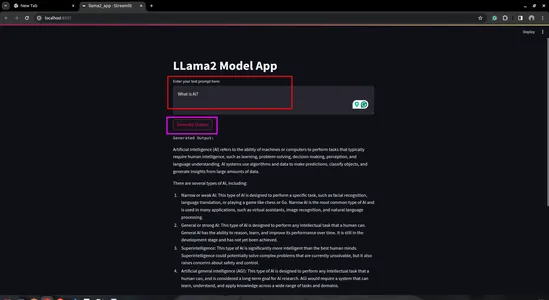
st.title('LLama2 Model App')
# Text input for user prompt
user_prompt = st.text_area('Enter your text prompt here:', '')
# Button to trigger model invocation
if st.button('Generate Output'):
payload = {
"prompt": user_prompt,
"max_gen_len": 512,
"temperature": 0.5,
"top_p": 0.9
}
body = json.dumps(payload)
model_id = "meta.llama2-70b-chat-v1"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
generation = response_body['generation']
st.text('Generated Output:')
st.write(generation)
- Exécutez l’application Streamlit :
- Enregistrez votre script Python et exécutez-le à l’aide de la commande Streamlit dans votre terminal :
streamlit run llama2_app.py
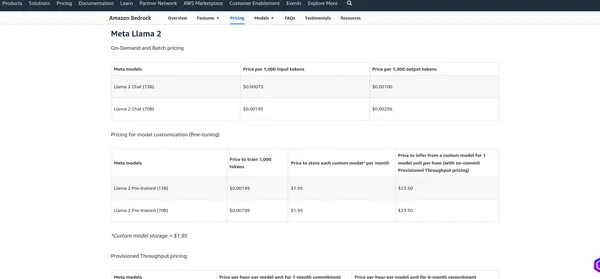
Tarification du substrat rocheux AWS
La tarification d’AWS Bedrock dépend de divers facteurs et des services que vous utilisez, tels que l’hébergement de modèles, les demandes d’inférence, le stockage de données et le transfert de données. AWS facture généralement en fonction de l’utilisation, ce qui signifie que vous ne payez que ce que vous utilisez. Je vous recommande de consulter la page de tarification officielle, car AWS peut modifier sa structure tarifaire. Je peux vous fournir les tarifs actuels, mais il est préférable de vérifier les informations sur la page officielle pour obtenir les détails les plus précis.
Objectif LlaMA 2
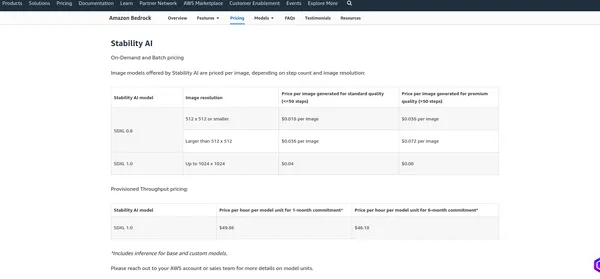
IA de stabilité
Conclusion
Ce blog s’est penché sur le domaine de l’IA générative, en se concentrant spécifiquement sur deux puissants modèles LLM : Stable Diffusion et LLamV2. Nous avons également exploré AWS Bedrock en tant que plate-forme de création d’API de modèle LLM. À l’aide de ces API, nous avons démontré comment écrire du code pour interagir avec les modèles. De plus, nous avons utilisé le terrain de jeu AWS Bedrock pour pratiquer et évaluer les capacités des modèles.
Dès le début, nous avons souligné l’importance de sélectionner la bonne région au sein d’AWS Bedrock, car ces modèles peuvent ne pas être disponibles dans toutes les régions. À l’avenir, nous avons proposé une exploration pratique de chaque modèle LLM, en commençant par la création de notebooks Jupyter, puis en passant au développement d’applications Streamlit.
Enfin, nous avons discuté de la structure tarifaire d’AWS Bedrock, soulignant la nécessité de comprendre les coûts associés et de nous référer à la page de tarification officielle pour des informations précises.
Points clés à retenir
- Stable Diffusion et LLAMV2 sur AWS Bedrock offrent un accès facile à de puissantes fonctionnalités d’IA générative.
- AWS Bedrock fournit une interface simple et une documentation complète pour une intégration transparente.
- Ces modèles ont des fonctionnalités clés et des cas d’utilisation différents dans divers domaines.
- N’oubliez pas de choisir la bonne région pour accéder aux modèles souhaités sur AWS Bedrock.
- La mise en œuvre pratique de modèles d’IA génératifs tels que Stable Diffusion et LLAMv2 offre une efficacité sur AWS Bedrock.
Questions fréquemment posées
R. L’IA générative est un sous-ensemble de l’intelligence artificielle axé sur la création de nouveaux contenus, tels que des images, du texte ou du code, plutôt que sur la simple analyse des données existantes.
A. Stable Diffusion est un modèle d’IA génératif qui produit des images photoréalistes à partir d’invites de texte et d’images en utilisant la technologie de diffusion et l’espace latent.
R. AWS Bedrock fournit des API pour la gestion, la formation et le déploiement de modèles, permettant aux utilisateurs d’accéder à de grands modèles de langage comme LLAMv2 pour diverses applications.
R. Vous pouvez accéder aux modèles LLM sur AWS Bedrock à l’aide des API fournies, par exemple en appelant le modèle avec des paramètres spécifiques et en recevant la sortie générée.
A. Stable Diffusion peut générer des images de haute qualité à partir d’invites de texte, fonctionne efficacement en utilisant l’espace latent et est accessible à un large éventail d’utilisateurs.
Les médias présentés dans cet article n’appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l’auteur.